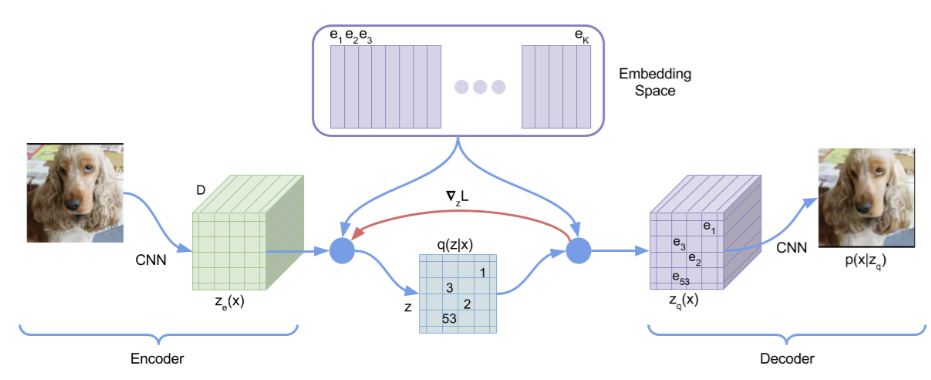
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
|
import torch
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
from torch.utils.data import DataLoader, Dataset
import wandb
# Initialize wandb
wandb.init(project="vq-single-codebook", config={
"vector_dim": 64,
"num_vectors": 10000,
"num_embeddings": 1024,
"embedding_dim": 64,
"batch_size": 32,
"num_epochs": 50,
"learning_rate": 0.0005
})
config = wandb.config
# create dataset
class VQDataset(Dataset):
def __init__(self, vector_dim, num_vectors):
super().__init__()
data = torch.randn(num_vectors, vector_dim)
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# dataset = vq_Dataset(config['vector_dim'], config['num_vectors'])
# vq_DataLoader = DataLoader(dataset, batch_size=32, shuffle=True)
# Vector Quantization Model
class VQ(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super().__init__()
self.embedding = nn.Embedding(num_embeddings, embedding_dim)
def forward(self, x):
x.requires_grad_(True)
# print(self.embedding.weight.shape)
distances = torch.cdist(x.unsqueeze(1), self.embedding.weight.unsqueeze(0))
indices = torch.argmin(distances, dim=-1)
quantized = self.embedding(indices)
# Straight-through estimator
quantized = quantized + (quantized - x).detach()
# Compute loss
commitment_loss = F.mse_loss(x, quantized.detach())
codebook_loss = F.mse_loss(quantized, x.detach())
loss = commitment_loss + codebook_loss
return quantized, loss, indices
# Training function
def train_vq(model, dataloader, config):
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
for epoch in range(config.num_epochs):
total_loss = 0
for batch in dataloader:
optimizer.zero_grad()
quantized, loss, _ = model(batch)
reconstruction_loss = F.mse_loss(quantized, batch)
total_loss = loss + reconstruction_loss
total_loss.backward()
optimizer.step()
wandb.log({
"epoch": epoch + 1,
"total_loss": total_loss.item(),
"commitment_loss": loss.item(),
"reconstruction_loss": reconstruction_loss.item()
})
print(f"Epoch {epoch+1}/{config.num_epochs}, Loss: {total_loss.item():.4f}")
# Create dataset and dataloader
dataset = VQDataset(config.vector_dim, config.num_vectors)
dataloader = DataLoader(dataset, batch_size=config.batch_size, shuffle=True)
# Create and train the VQ model
model = VQ(config.num_embeddings, config.embedding_dim)
train_vq(model, dataloader, config)
# Close wandb run
wandb.finish()
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
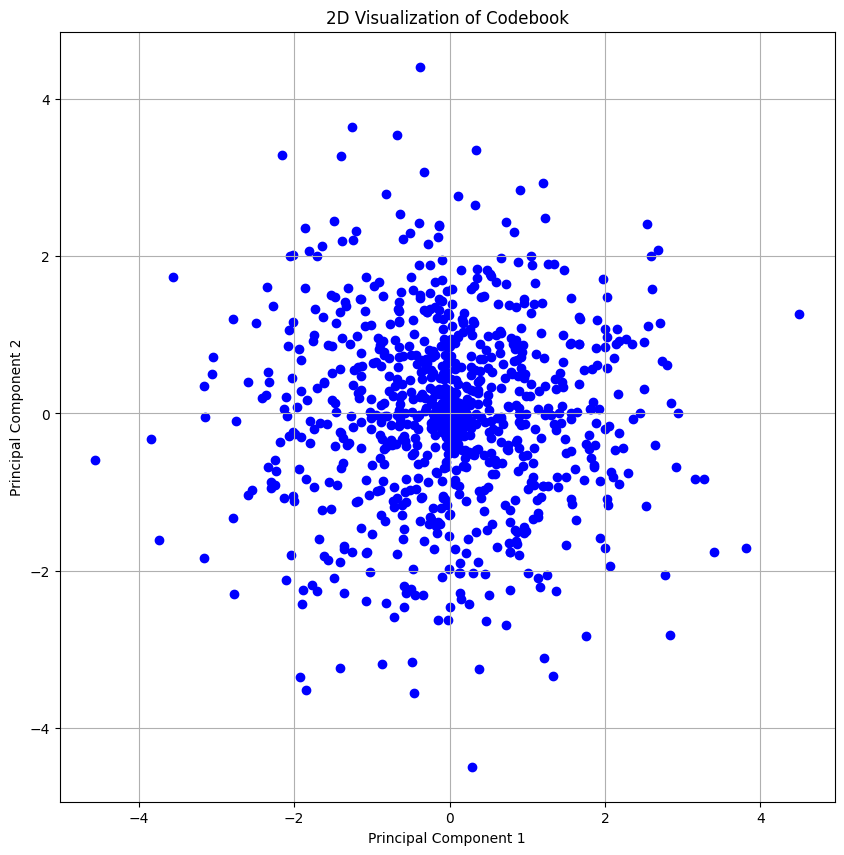
def visualize_codebook(model):
codebook = model.embedding.weight.detach().cpu().numpy()
pca = PCA(n_components=2)
codebook_2d = pca.fit_transform(codebook)
plt.figure(figsize=(10, 10))
plt.scatter(codebook_2d[:, 0], codebook_2d[:, 1], c='blue', marker='o')
plt.title('2D Visualization of Codebook')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.grid(True)
plt.show()
visualize_codebook(model)
|