语音评估指标及工具
声音质量指标:
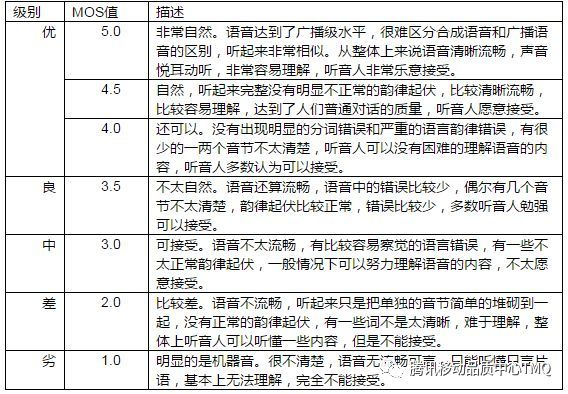
MOS (Mean Opinion Score)
虽然这通常是主观评分,但也有自动MOS预测工具,如AutoMOS。
PESQ (Perceptual Evaluation of Speech Quality):
用于评估语音质量,特别是在电信系统中。
STOI (Short-Time Objective Intelligibility):
评估语音的可懂度
声音相似度指标:
- Speaker Similarity Score:通常使用说话人验证模型(如d-vector或x-vector)来计算。
- Voice Conversion Score:评估转换后的声音与目标声音的相似度。
发音准确度指标:
- PER (Phoneme Error Rate):评估音素级别的准确性。
- MCD (Mel Cepstral Distortion):测量合成语音与参考语音之间的频谱差异。
韵律指标:
- F0 RMSE (Root Mean Square Error):评估基频(音高)的准确性
- V/UV error (Voiced/Unvoiced error):评估浊音和清音的判断准确性。
整体性能指标:
- WER (Word Error Rate):虽然主要用于ASR,但也可用于评估TTS的可懂度。
- CER (Character Error Rate):类似WER,但在字符级别评估。
特定于声音克隆的指标:
- EER (Equal Error Rate):在说话人验证任务中使用,评估克隆声音的欺骗性。
EER是FAR和FRR相等时的错误率。
- FAR (False Acceptance Rate) 和 FRR (False Rejection Rate):在声音克隆任务中。
FAR = (错误接受的克隆声音样本数) / (总克隆声音样本数)
- FRR(False Rejection Rate):FRR表示系统错误地拒绝了真实声音的比率。
FRR = (错误拒绝的真实声音样本数) / (总真实声音样本数)
声学特征相似度:
- MFCC距离:比较原始声音和合成声音的MFCC(Mel频率倒谱系数)。
- Spectral Convergence:评估频谱的相似度。
自然度指标:
- Naturalness MOS:评估合成语音的自然程度。
- Prosody MOS:评估韵律的自然度。
测试工具
音色相似度
resemblyzer
resemblyzer是一个可以计算音色向量的开源仓库,它使用深度学习模型来提取声音的高级表示,对音频进行decoder从而得到音色向量,通过计算音色向量之间的余弦相似度可以得到两个音频的相似分数。
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from resemblyzer import VoiceEncoder, preprocess_wav
from pathlib import Path
# 加载音频文件
wav_fpath = Path("path/to/audio/file.wav")
wav = preprocess_wav(wav_fpath)
# 初始化编码器
encoder = VoiceEncoder()
# 提取音频的嵌入向量
embed = encoder.embed_utterance(wav)
# 现在可以使用这个嵌入向量进行相似度比较
|
speechbrain
SpeechBrain是另一个强大的开源工具包,用于语音处理任务,包括声音相似度比较。虽然搜索结果中没有直接提到SpeechBrain,但根据我的知识,我可以为您介绍它的一些特点:
- SpeechBrain提供了多种预训练模型,包括说话人识别模型,可以用于声音相似度比较。
- 它支持提取说话人嵌入向量,这些向量可以用于计算不同音频之间的相似度。
- SpeechBrain的模型通常输出说话人嵌入向量,这是一种编码不同人语音相似性的向量表示。[2]
使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
|
import torch
from speechbrain.pretrained import EncoderClassifier
# 加载预训练的说话人识别模型
classifier = EncoderClassifier.from_hparams(source="speechbrain/spkrec-ecapa-voxceleb")
# 提取两个音频文件的嵌入向量
embedding1 = classifier.encode_batch(torch.tensor([waveform1]))
embedding2 = classifier.encode_batch(torch.tensor([waveform2]))
# 计算相似度(例如,使用余弦相似度)
similarity = torch.nn.functional.cosine_similarity(embedding1, embedding2)
|
测试下来speechbrain的分数差别比resemblyzer要大,但似乎有些不大准确的地方
PER (Phoneme Error Rate)&WER(Word Error Rate)测试工具:
jiwer
jiwer通常用来计算WER和PER
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import jiwer
def calculate_per(reference, hypothesis):
reference = "sil dh ax cl t r ey n r ae n f ae s cl t sil"
hypothesis = "sil dh ax cl t r ey n r ae n s l ow sil"
return jiwer(reference, hypothesis)
def calculate_chinese_wer(self, reference, hypothesis):
"""计算中文WER"""
reference = clean_text(reference)
hypothesis = clean_text(hypothesis)
ref_tokens = ' '.join(jieba.cut(reference))
hyp_tokens = ' '.join(jieba.cut(hypothesis))
ref_tokens = self.transformation(ref_tokens)
hyp_tokens = self.transformation(hyp_tokens)
return jiwer.wer(ref_tokens, hyp_tokens)
|
leven
leven 是一个Python包,可以用来计算PER和WER。它基于Levenshtein距离算法,能够产生与其他标准工具相同的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
from leven import levenshtein
def calculate_error_rate(reference, hypothesis):
"""
计算错误率 (可用于WER或PER)
Args:
reference: 参考序列(列表)
hypothesis: 预测序列(列表)
Returns:
error_rate: 错误率
num_errors: 编辑距离
"""
# 计算编辑距离
distance = levenshtein(reference, hypothesis)
# 错误率 = 编辑距离 / 参考序列长度
error_rate = distance / len(reference) if len(reference) > 0 else 0
return error_rate, distance
def calculate_wer(reference_text, hypothesis_text):
"""
计算词错误率 (WER)
Args:
reference_text: 参考文本
hypothesis_text: 预测文本
Returns:
wer: 词错误率
num_errors: 编辑距离
"""
# 将文本分割成单词列表
reference_words = reference_text.strip().split()
hypothesis_words = hypothesis_text.strip().split()
return calculate_error_rate(reference_words, hypothesis_words)
def calculate_per(reference_phones, hypothesis_phones):
"""
计算音素错误率 (PER)
Args:
reference_phones: 参考音素序列
hypothesis_phones: 预测音素序列
Returns:
per: 音素错误率
num_errors: 编辑距离
"""
# 如果输入是字符串,先分割成列表
if isinstance(reference_phones, str):
reference_phones = reference_phones.strip().split()
if isinstance(hypothesis_phones, str):
hypothesis_phones = hypothesis_phones.strip().split()
return calculate_error_rate(reference_phones, hypothesis_phones)
|
